Show HN: I built a sub-20ms Crypto Aggregator in Go
How a 19yo solo dev built a real-time system handling 1000 pairs on a 4-core VPS with 500MB RAM.
How a 19yo solo dev built a real-time system handling 1000 pairs on a 4-core VPS with 500MB RAM.
Hi HN! I’m a 19-year-old software engineer, and for the past year, I’ve been heavily involved in algorithmic trading, specifically writing configurations for Hummingbot and FreqTrade.
If you've ever built a market-making bot, you know the pain. Calculating grid parameters, deriving real-time indicators across multiple exchanges, and normalizing chaotic OHLCV data is a nightmare. Existing public APIs like CoinGecko or GeckoTerminal are full of noisy data and rate limits. The professional, HFT-grade feeds? They easily cost upwards of $2,000 a month.
I just wanted a clean, deterministic API that gives me aggregated prices, cross-exchange spreads, and technical indicators (RSI, MACD, ATR, Bollinger Bands) in real-time, without bankrupting me.
So, I spent the last two months locked in my IDE. With my friend (a marketer who bravely volunteered to be my QA tester and lab rat), I built LimpioTerminal: a real-time crypto market data infrastructure written in Go.
Today, it runs on a single 4-core VPS in Germany, consumes barely 500MB of RAM, and delivers indicator calculations across 1000+ pairs with a 12ms latency (measured from Frankfurt(Germany) to the Amsterdam(Netherlands)).
Here is a deep dive into the architecture, the fuckups I made along the way, and why I chose "pragmatism over nanoseconds."
When you are dealing with WebSockets from 7 different exchanges (Binance, OKX, Bybit, Kraken, Gate.io, Bitget, KuCoin), the incoming tick rate is relentless. If you try to write every tick to a relational database, your disks will melt. If you poll a database for every API request, your latency will skyrocket.
The core principle of Limpio is absolute separation of the hot layer (Redis + WS stream) from the cold layer (TimescaleDB).
Service Topology
NEW_CANDLE:*), grabs the latest candle window, recalculates indicators in parallel, and stores the results back in Redis.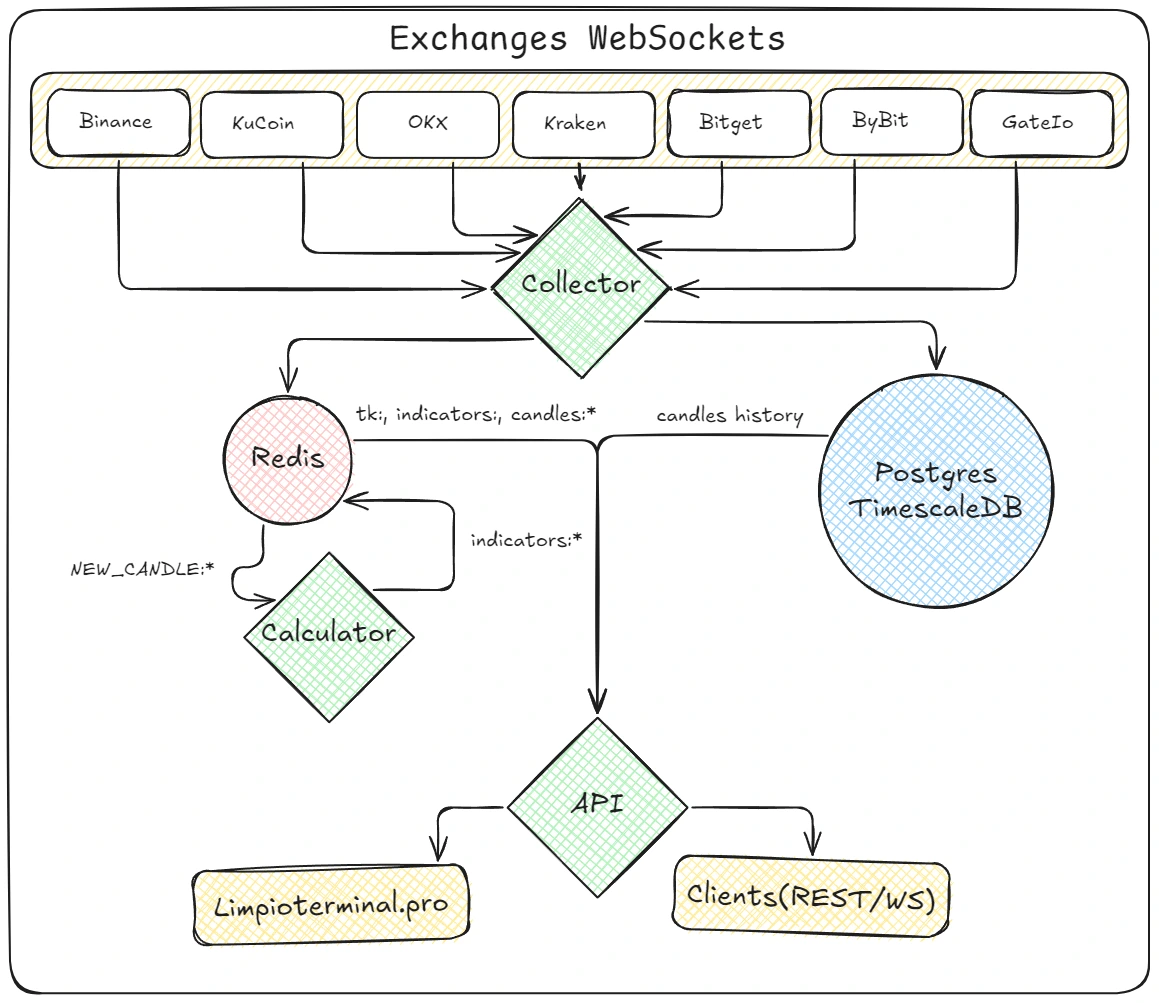
Here is the flow of a single tick through the system:
When I first wrote the WebSocket Manager, I was in a rush. I wanted to see data flowing. I spun up goroutines for every subscription, connected to the exchanges, and watched the logs light up.
Five minutes later, my 32GB local machine froze. The OOM killer nuked the process.
At the time, I was trying to track 3,000 pairs. Exchanges like MEXC and Gate.io have limits on how many subscriptions you can pack into a single WS payload. I wasn't properly cleaning up temporary subscriptions or closing zombie connections. Goroutines were piling up in the thousands.
I had to rewrite the WSManager to be defensively chunked and explicitly aware of memory leaks.
// CRITICAL: Prevent memory leak by limiting map size
func (m *WSManager) SubscribeToPair(symbol string) {
m.mu.Lock()
if _, ok := m.tempSubs; ok {
m.tempSubs = time.Now().Add(m.subDuration)
m.mu.Unlock()
return
}
// If we're at max capacity, remove oldest entries first
if len(m.tempSubs) >= m.maxTempSubs {
var oldestSymbol string
var oldestTime time.Time
first := true
for sym, expiry := range m.tempSubs {
if first || expiry.Before(oldestTime) {
oldestSymbol = sym
oldestTime = expiry
first = false
}
}
if oldestSymbol != "" {
delete(m.tempSubs, oldestSymbol)
m.logger.Debug("Removed oldest subscription %s to prevent memory leak", oldestSymbol)
}
}
// ...
}I also added aggressive integration tests specifically for memory profiling (TestIntegrationMemoryLeaks), measuring allocations before and after massive subscription bursts, forcing the Garbage Collector to run, and failing the test if the delta exceeds 50MB. Now, the production system idles at ~500MB of RAM.
If you aggregate crypto data, you quickly learn which exchanges have competent infrastructure and which ones are held together by duct tape.
KuCoin is a masterpiece. I can request real-time ticks for ~1,000 pairs over a single connection, and it streams flawlessly for days without a single hiccup.
MEXC is my personal enemy. Their WebSocket connections drop arbitrarily. Even if you stick to their ping intervals and try to request a modest batch of 50 pairs, the connection will drop arbitrarily. I had to write a highly protective read loop with exponential backoff specifically for them, BUT EVEN THAT didn't help — I just froze the integration so as not to waste time.
Because of these inconsistencies across exchanges, I introduced the concept of Data Quality Scoring directly into the API payload. If you request data for a pair, Limpio tells you exactly how many sources are currently healthy and contributing to the aggregated price.
{
"data": {
"sources": [
"binance",
"bybit",
"kraken",
"bitget",
"kucoin"
]
},
"pair": "USDC-USDT",
"success": true
}When you feed data to an algorithmic trading bot, a single bad tick can liquidate your portfolio. What happens if an exchange's API glitches and sends a price of 0.0001 for Bitcoin for exactly one millisecond?
If you just average the prices across exchanges, that zero will drag the aggregated price down, triggering stop-losses.
To solve this, I implemented Neighbor Protection. The system calculates the median price across all live exchange feeds. If one exchange deviates from the median by more than a specified threshold (e.g., 20%), and no other exchange confirms this movement, that source is dynamically quarantined and dropped from the aggregation pool.
func CheckNeighborProtection(dataPoints[]*PairData, thresholdPercent float64) *NeighborProtectionResult {
// ... calculate median
medianPrice := sortedPrices
for _, dp := range dataPoints {
deviationPerc := math.Abs((dp.CurrentPrice-medianPrice)/medianPrice) * 100
if deviationPerc > thresholdPercent {
// Do other exchanges confirm this crash?
similarCount := 0
for _, other := range dataPoints {
if other == dp { continue }
otherDeviation := math.Abs((other.CurrentPrice-medianPrice)/medianPrice) * 100
if otherDeviation > thresholdPercent*0.5 {
similarCount++
}
}
// If isolated, it's an exchange API failure. Quarantine it.
if similarCount == 0 {
return &NeighborProtectionResult{
IsAnomaly: true,
AnomalySource: dp.Sources,
Reason: fmt.Sprintf("deviation of %.2f%% not confirmed", deviationPerc),
}
}
}
}
return &NeighborProtectionResult{IsAnomaly: false}
}Initially, I tried to persist every single 1-minute candle to the database. I severely overestimated my VPS. The disk IOPS were going crazy, the database bloated, and queries were slowing down.
I introduced TimescaleDB, which helped massively with hypertables and compression. But then I asked myself: Why do I even need 1-minute candles in cold storage?
The hot path (real-time indicators) only needs the last 1,000 minutes to calculate a 200-period SMA or MACD. That fits perfectly in a Redis List using LPUSH and LTRIM. For historical graphs and long-term backtesting, 1-hour candles are more than enough.
So, I killed the 1-minute cold storage. I wrote a migration script to aggregate everything into 1-hour buckets.
-- Step 3: Aggregate 1m -> 1h into candles_new
INSERT INTO candles_new (time, pair_id, exchange_id, open, high, low, close, volume)
SELECT
time_bucket('1 hour', time) AS time,
pair_id,
0 AS exchange_id,
(array_agg(open ORDER BY time ASC)) AS open,
max(high) AS high,
min(low) AS low,
(array_agg(close ORDER BY time DESC)) AS close,
sum(volume) AS volume
FROM candles
GROUP BY time_bucket('1 hour', time), pair_id;Today, my TimescaleDB contains data for all pairs starting from January 1, 2025, and the entire database weighs exactly 543 MB. It's incredibly fast and cheap to host.
But what if the WebSocket disconnects and we miss data? I wrote a GapFiller service that routinely checks TimescaleDB for temporal gaps (e.g., jump from 02:00 to 05:00). It makes targeted REST calls to KuCoin (which allows fetching up to 1500 historical candles per request), aggregates them into hours, and patches the database automatically.
Because Limpio calculates technical indicators (RSI, MACD, Bollinger Bands, ATR, etc.) on the fly, I needed to figure out the caching layer.
The Calculator is a batch-processing engine. It listens to Redis, grabs a batch of 50-100 pairs, and distributes the math across a pool of 8 worker goroutines.
I debated whether to use pure in-memory state or rely on Redis + L1 cache (Ristretto). Being a 19-year-old inexperienced developer, I decided to ask a Lead Architect of a major Binance algorithmic suite regarding caching strategies on LinkedIn. To my surprise, he replied with a pragmatism check:
In the extremely volatile crypto environment, where exchanges drop connections randomly, robustness beats nanoseconds. If my service crashes, I don't want to spend 10 minutes querying TimescaleDB to rebuild the 1000-minute moving averages for 1000 pairs. By keeping the hot-window in Redis, the API can restart and resume serving sub-20ms responses instantly.
I kept Redis. I also kept the L1 Ristretto cache inside the Go process to avoid unnecessary network hops for identical requests happening in the same millisecond.
func (w *Worker) GetIndicatorsWithCache(ctx context.Context, pairID string) (string, bool) {
// Check L1 cache first (Ristretto)
if w.l1Cache != nil {
cacheKey := fmt.Sprintf("indicators:%s", pairID)
if val, found := w.l1Cache.Get(cacheKey); found {
if str, ok := val.(string); ok {
w.metrics.RecordCache(true)
return str, true
}
}
}
w.metrics.RecordCache(false)
// Fallback to Redis L2
return GetIndicators(ctx, w.rc, pairID)
}The original reason I started this project was to automate Grid Trading setups. I ported my old JS logic into Go. Now, hitting GET /SOL-USDT/grid-calculator analyzes of 1H candles, calculates the ATR and Bollinger Bands, determines the macro trend (UP/DOWN/SIDEWAYS), and spits out mathematically optimal grid parameters.
{
"success": true,
"pair": "SOL-USDT",
"timestamp": 1771536498,
"input_parameters": {
"base_price": 84,
"range_percent": 5,
"period_days": 5,
"exchange_fee": 0.35,
"timeframe": "1h",
"grid_mode": "geometric",
"capital_usdt": 1250,
"min_notional": 10
},
"recommended_parameters": {
"range_percent": 12,
"grids": 24,
"step_percent": 0.20833333333333334,
"step_usd": 0.175,
"profit_per_cycle": -0.4916666666666666,
"profit_per_cycle_usd": -0.4129999999999999,
"daily_cycles": 5.233451953256761,
"daily_roi_percent": -2.573113877017907,
"apy_simple_percent": -939.1865651115361,
"apy_percent": -99.9926248627352,
"source": "Bollinger Bands"
},
"range_calculation": {
"lower_bound": 79.8,
"lower_percent": -5,
"base_price": 84,
"upper_bound": 88.2,
"upper_percent": 5,
"total_range": 8.400000000000006,
"step_size_1percent": 0.84
},
"capital_split": {
...
},
"min_notional_check": {
...
},
"grid_metrics": {
...
},
"warning": "Configuration is unprofitable: expected profit per cycle is <= 0. Adjust grid step, range or fees."
}If the market is in a STRONG_DOWN trend, the API injects a warning into the JSON payload advising the bot to widen the grid or halt trading entirely.
DANGER
The Grid Calculator is still under active development! I am still testing it and trying to turn it into a full-fledged tool, not just a demo. Please do not try to trade based on data from this calculator, as it is not yet fully debugged.
Creating LimpioTerminal taught me that you don't need a huge Kubernetes cluster to process financial data.
A well-designed Go monolith, strict separation of “hot” and “cold” data, aggressive batch processing, and a pragmatic approach to caching allow you to process a huge amount of data on a standard 4-core machine.
The API is already operational. You can check the latency yourself right now via RapidAPI or our Sandbox. If this post gains popularity, I will release the source code for the Websocket-Manager module next week.
I would be happy to hear your opinions, criticism, or comments!
Sincerely, Dmitrii